

As climate change intensifies, scientists are working to find the best performing methods, algorithms, or models to simulate the impact of high temperature and/or limited water availability on crop growth, development and productivity. The complexity of plant-environment interactions makes this difficult, but new research has shown that the integration of machine learning and crop modelling may provide the answers needed.
Dr. Ioannis Droutsas, Research Fellow at the University of Leeds, and coauthors embedded machine learning (ML) algorithms into a process-based crop model to create a new crop modelling/ML framework with high performance in the representation of crop response to a wide range of environments, including stress conditions.
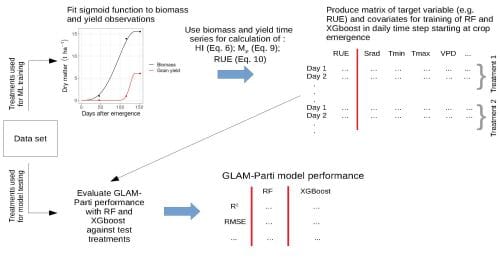
The authors modified the existing process-based crop model GLAM-Parti by embedding machine learning algorithms to estimate variables that regularly escape the crop model’s predictive capacity. . ML was used for daily predictions of radiation use efficiency, the rate of change of harvest index and the phenological stage.
For the assessment of the new GLAM-Parti-ML framework, the authors used an existing data set for one cultivar of wheat grown under a wide range of temperatures, solar radiation, and atmospheric humidity conditions, including exposure to heat stress. Half of the data was used to train the machine learning algorithms and the other half to test the model.
The model was run with the weather inputs temperature, solar radiation and vapor pressure deficit, the most significant weather determinants of wheat growth for irrigated, well fertilized conditions. The outputs of biomass and grain yield, as well as the days to anthesis and maturity were compared to the end-of-season field measurements.
The team applied Random Forests and Extreme Gradient Boosting. Both ML models exhibited high efficiency in learning the patterns between inputs and crop performance (in terms of radiation use efficiency) during the course of the growing season. This resulted in good model skill for crop biomass; GLAM-Parti-ML reproduced 98% of the observed variance in both biomass and grain yield and the model error was less than 20%. Moreover, the model reproduced at least 98% of the observed variance in the days to anthesis and maturity with less than 11% error. Nevertheless, the onset of both phenological stages was underestimated, thus predicting anthesis and maturity earlier than observed.
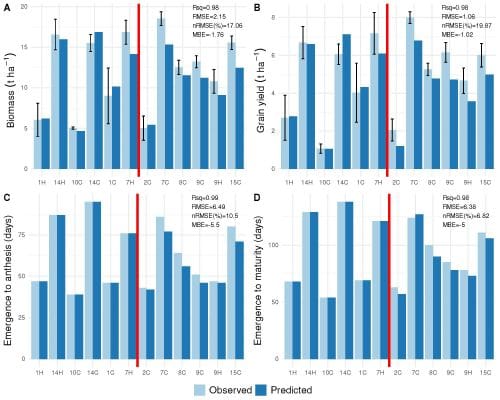
Next, GLAM-Parti was compared to its predecessor, GLAM, a process-based crop model with no integration of machine learning. GLAM was calibrated with 100% of the data and GLAM-Parti with only 50%. Nevertheless, GLAM-Parti-ML had lower error values for biomass, yield, and the days to maturity and anthesis, indicating that the machine learning parameterizations improved the model despite being trained on only half of the data.
To further evaluate GLAM-Parti-ML, the authors used a second data set of three cultivars of wheat grown in many field experiments across six countries. Again, half of the data was used to train the machine learning algorithms and the other half to test the model.
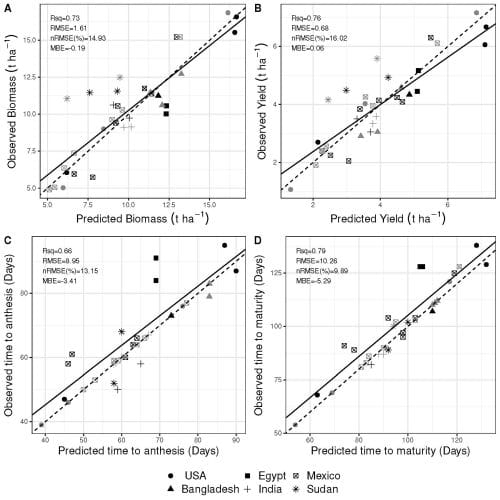
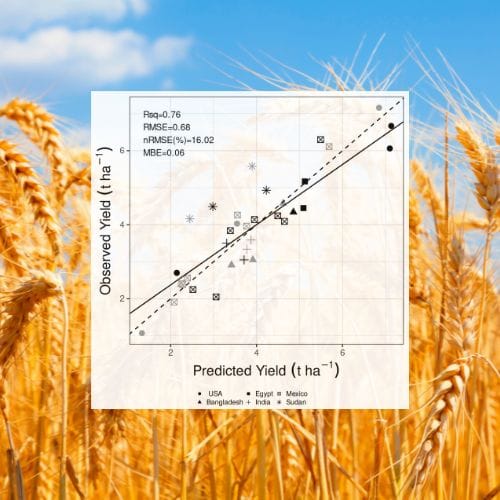
Once more, the model had excellent performance. It reproduced 73% of the variation in biomass across locations and cultivars with 15% error and 76% of grain yield variation with 16% error. The crop phenology was more accurate for the days to maturity (9.9% error) than anthesis (13.2% error). There was again negative bias in the prediction of both phenological stages.
Droutsas concludes, “the use of a larger training data set would greatly improve the model simulations. However, few data sets with the required measurements exist.”
READ THE ARTICLE:
Ioannis Droutsas, Andrew J Challinor, Chetan R Deva, Enli Wang, Integration of machine learning into process-based modelling to improve simulation of complex crop responses, in silico Plants, 2022, diac017, https://doi.org/10.1093/insilicoplants/diac017


