


There is a tool that can guide plant breeding to increase yields to meet the demands of a growing population under a changing climate: ecophysiological crop models. These models simulate plant development based on various environmental and management inputs. The traits that these models simulate are based on mathematical algorithms that represent underlying physiological processes that drive the growth and development of crops from planting to maturity.
Ecophysiological crop models provide valuable information, but some traits cannot be simulated well because they require parameter values that are difficult to measure, unknown, or vary with cultivar. These values are important: the performance of crop models depends largely on the level of detail in the input information available for model parameterization.
Fortunately, ecophysiological crop models can be integrated with and informed by genomic prediction algorithms, which can link genes to the parameters that control the physiological processes. The best class of parameters to target with genomic prediction algorithms are called “genotype-specific parameters (GSPs)”. This genotype-to-phenotype integration would allow breeders to select genes controlling traits that are difficult to select phenotypically.
While the integration of ecophysiological crop models and genomic prediction has great promise, relatively little work has been done in this effort. Former Postdoctoral Fellow at Kansas State University Pratishtha Poudel, now an Assistant Professor at Purdue University, and colleagues, theorize that this may be due to limited overlap between the ecophysiological crop modeling and genomic prediction communities.
According to the authors, there are many different algorithms and no one genomic prediction algorithm is the best fit across different species and traits. Therefore, selecting the appropriate genomic prediction algorithm can be daunting. Their review article, published in in silico Plants, intends to close that gap by familiarizing ecophysiological crop modelers with genomic prediction algorithms.
They considered the following genomic prediction algorithms:
- Bayes A and B
- best linear unbiased predictor (BLUP)
- LASSO
- marker assisted selection (MAS)
- reproducing kernel Hilbert space (RKHS)
The paper guides readers in choosing the most suitable genomic prediction algorithm for different genotype-specific parameters based on the following criteria:
1) Choose the genomic prediction algorithm based on the complexity of the genetic architecture of the trait of interest (in this case, each GSP).
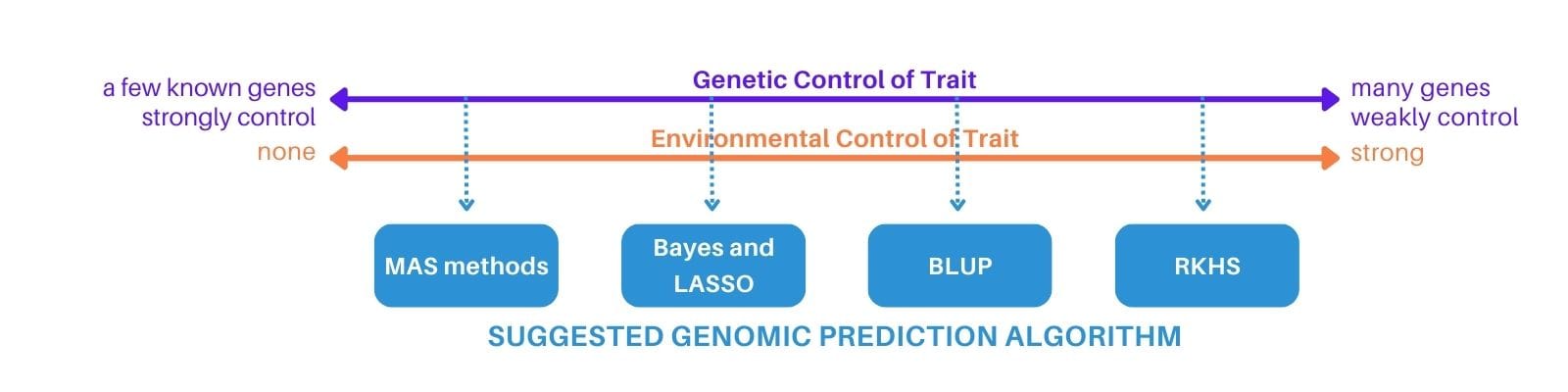
The user must ask how many genes control the trait and how strongly. Also, they must consider to what extent gene expression is controlled by the environment. Information on number and size of QTLs from QTL studies are used to infer a trait’s genetic architecture.
2) Determine how to estimate the genotype-specific parameters.
Once a genomic prediction algorithm is selected (or a few candidates), the genotype-specific parameters can be estimated using one of two approaches which differ in their computational complexity and efficiency of the estimation process.
Objective functions are used to measure the differences between the observed and predicted parameters values – each iteration should bring them closer to convergence.
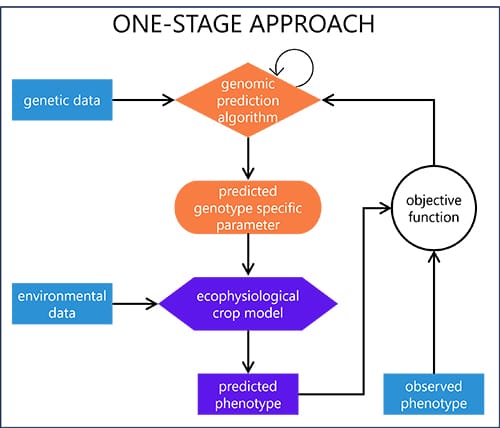
One-stage approach: Genotype-specific parameters and the genomic prediction algorithm meant to predict them are fitted simultaneously. Each iteration of the genomic prediction algorithm requires a reevaluation of the ecophysiological crop model predicted phenotype for each genotype and environment via objective functions.
- Pros: Combined genetic and phenotypic data between genotypes leads to better estimates of genotype-specific parameters
- Cons: Lower computational efficiency
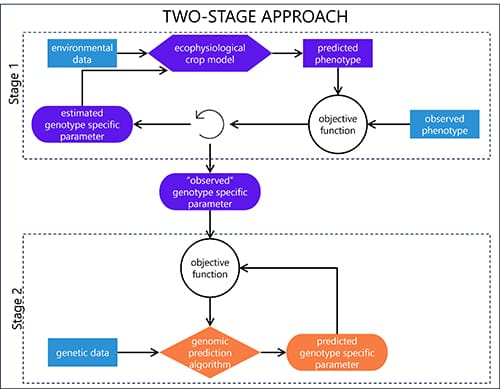
Two-stage approach: Estimated genotype-specific parameters are estimated for the ecophysiological crop model first, then the genomic prediction algorithm is fitted.
- Pros: Higher computationally efficiency
- Cons: Can create biased genotype-specific parameters estimates upon which the second stage of estimation would be based if data has high variance (e.g., from incomplete data such when not all genotypes are grown in trials conducted over different environments).
3) Examine the capacity to incorporate prior genetic information.
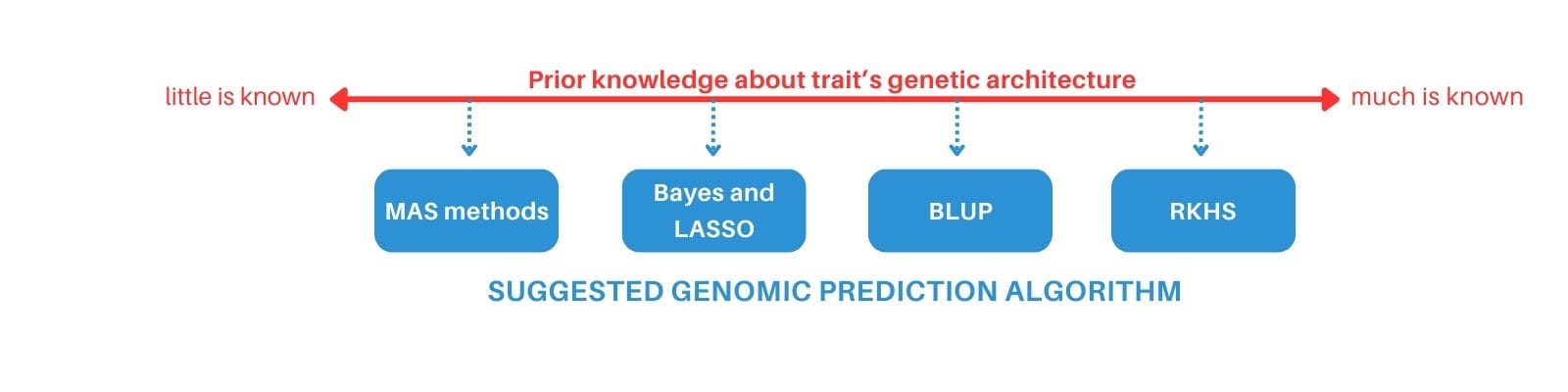
When additional information about a trait’s genetic architecture is known, users should choose an algorithm that can incorporate that information. This information can include markers or genes where effects are known from traits that are commonly measured and high quantities of data. If little information is available, simple prediction algorithms would be most appropriate because it is likely that only prominent major genetic effects will be recoverable from the data. If much is known, such as from high throughput phenotyping, a more complex method can be used.
Poudel concludes: “Estimating GSPs in ecophysiological crop models with genomic prediction models will help combine genotypic and phenotypic information for a comprehensive genotype-to-phenotype picture. In this article, we take a key step towards bringing the genomic prediction and ecophysiological modeling communities together and explore avenues to develop such combined prediction algorithms.”
READ THE ARTICLE:
Pratishtha Poudel, Bryan Naidenov, Charles Chen, Phillip D Alderman, and Stephen M Welch. Integrating genomic prediction and genotype specific parameter estimation in ecophysiological models: overview and perspectives, in silico Plants, 2023; diad007, https://doi.org/10.1093/insilicoplants/diad007




