

To feed a global population that is expected to reach 9.8 billion by 2050, food production will need to be increased by 70%. This challenge is further complicated by the negative impact of a changing climate on crop yield.
The development of new crop cultivars and identification of optimal management strategies can lead to increased yields and help mitigate the effects of climate change. Crop models will serve as a guiding tool in this work, enabling yield predictions based on factors such as the environment, management practices, and genetic traits.
For this purpose, a model is only as good as its predictions. While it could be tempting to disregard all models except for the one that has consistently demonstrated the highest accuracy in its predictions, a new study published in in silico Plants demonstrates that combining predictions from multiple models can result in enhanced prediction accuracy.
While combining predictions from multiple models has been found beneficial to determine complex traits, previous work has not tapped into models incorporating genetic and environmental interactions.
Daniel Kick and Jacob Washburn, both Research Geneticists at the USDA-ARS and University of Missouri, tested whether yield predictions could be improved using ensemble combinations of different model types, model numbers and model weighting schemes.
The authors included 8 types of models that incorporate genomic, environmental, and management information and represent 3 model categories in their work.
- Linear models are statistical models that assume a linear relationship between the input variables (genotypic and environmental data) and the output variable (yield). The model types considered in this study were linear fixed effects model (LM) and best linear unbiased predictor model (BLUP).
- Machine learning models make yield predictions based on patterns in the training data that may not be readily apparent using traditional statistical methods. The model types considered in this study were k-nearest neighbours (KNN), radius neighbour regression (RNR), SVR, and random forest regression (RF).
- Deep neural networks (DNNs) are a subset of machine learning that makes yield predictions using multiple stages of nonlinear data transformations, where features of the data are represented by successively higher and more abstract layers. These models may be optimized in different ways. The model types considered in this study were ‘consecutive optimization’ of subnetworks (DNN-CO) and ‘simultaneous optimization’ of all subnetworks at once (DNN-SO).
“These models have different assumptions about the data. Some may be better suited to phenotypic prediction than others and they might represent patterns in the data that others miss. This led us to train and test a diverse set of models,” explained Kick.
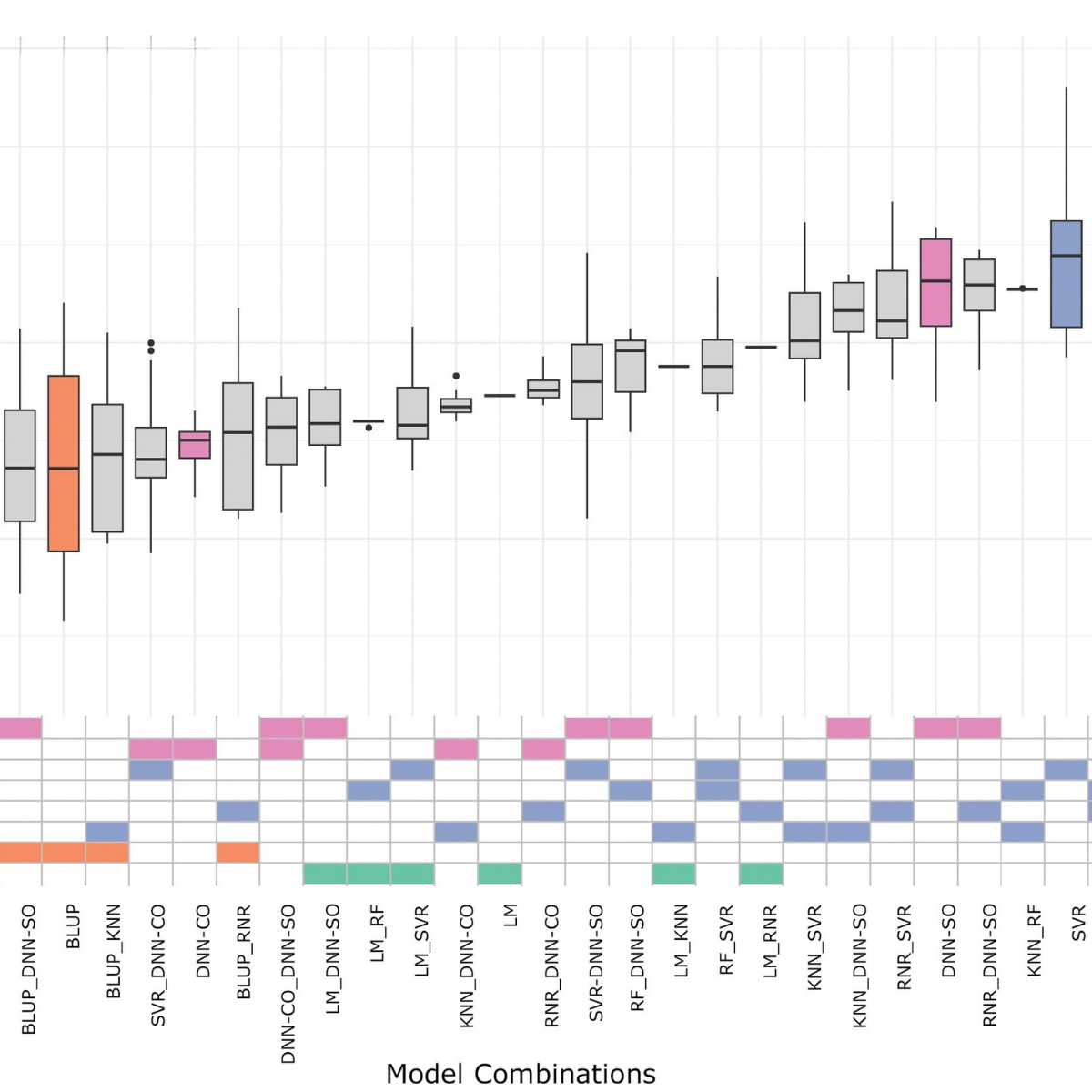
The authors sought to test the robustness of ensembling models and identify the types of models, along with the specific model averaging strategies, that were most effective at improving phenotypic prediction. The models were trained and tested to predict yield from genomic, environmental, and management data using a large maize data set. The ability of the individual models and model ensembles to accurately predict yield was measured by comparing root means squared error, which is proportional to the difference between the observed yield value and predicted yield value.
Ensemble models frequently predicted yield better than single models. Predictions from two-model ensembles had a 77% likelihood of having improved accuracy compared to predictions from any individual model on its own. However, employing a greater number of models was not a panacea. The benefit of adding additional models to the ensemble diminished with each model added. Moreover, the inclusion of additional models with predictions that closely align with those of the ensemble had minimal to no impact on accuracy.

The improvement in prediction accuracy of two-model ensembles was determined by the model types used. For example, most model predictions were improved to the greatest extent when combined with a high individual performing model (one of the two linear models or the ‘consecutive optimization’ DNN). Predictions for two-model ensembles were improved the least when they included the machine learning models, KNN and RNR, or the deep neural network ‘simultaneous optimization’ model.
The authors assessed the accuracy of combining modeled yield predictions using different weighting schemes. These included giving each model type equal weight or weighting each model inversely proportional to the standard deviation, variance, or root mean squared error of its predictions. Of the schemes examined, when all eight models were used in the same ensemble, weighting replicates inversely proportional to each replicates’ variance resulted in the lowest error. This scheme had 1.6% lower error than the best single model.
The best ensemble and weighting scheme for ensembles composed of 3 or more model types had a 7% lower error than the best single model. This ensemble was weighted by the inverse of each model’s expected error, and was composed of the two linear model types, the deep neural network ‘consecutive optimization’ model, and the machine learning RF and SVR models.
“Interestingly our best performing ensemble included two of the models (RF and SVR) that performed poorly on their own. An ensemble’s effectiveness comes in part from the difference in models’ predictions – one may be too high and another too low but together they’re on target. In the right context these models can increase accuracy.”
“Based on these results, where prediction is of primary importance, a researcher or breeder would, more often than not, be better off ensembling models together than using one model on its own” Kick explains.
READ THE ARTICLE:
Daniel R Kick, Jacob D Washburn, Ensemble of best linear unbiased predictor, machine learning and deep learning models predict maize yield better than each model alone, in silico Plants, Volume 5, Issue 2, 2023, diad015, https://doi.org/10.1093/insilicoplants/diad015


